Learn how to implement machine learning algorithms step by step, from data collection to model deployment, with practical tips and best practices.
Introduction
Machine learning (ML) is revolutionizing industries by enabling systems to learn from data, identify patterns, and make intelligent decisions. From powering recommendation engines on e-commerce platforms to detecting fraud in banking, machine learning algorithms have become a cornerstone of modern technology.
If you’ve ever wondered how to implement machine learning algorithms effectively, this guide will walk you through each step. Whether you’re a beginner or someone with coding experience, understanding the structured approach to building and deploying ML models can help you unlock new opportunities in data-driven decision-making.
Step 1: Define the Problem Clearly
Before diving into code, it’s essential to identify the business problem or research question you’re trying to solve. A well-defined problem ensures that you choose the right algorithm and collect the right type of data.
Ask yourself:
- Are you predicting numerical values (regression)?
- Are you classifying data into categories (classification)?
- Do you want to group similar data points (clustering)?
For example, predicting house prices requires regression, while detecting spam emails involves classification.
Step 2: Collect and Prepare Data
Data is the foundation of machine learning. Without quality data, even the most advanced algorithm won’t perform well.
Sources of Data:
- Company databases (sales records, customer interactions)
- Public datasets (e.g., Kaggle, UCI Machine Learning Repository)
- APIs (social media, financial data, weather services)
Data Preparation Includes:
- Cleaning: Removing duplicates, handling missing values, fixing errors
- Transformation: Normalizing values, encoding categorical variables
- Splitting: Dividing data into training, validation, and testing sets
Pro Tip: Always use at least 70% of your dataset for training and reserve 20–30% for testing and validation.
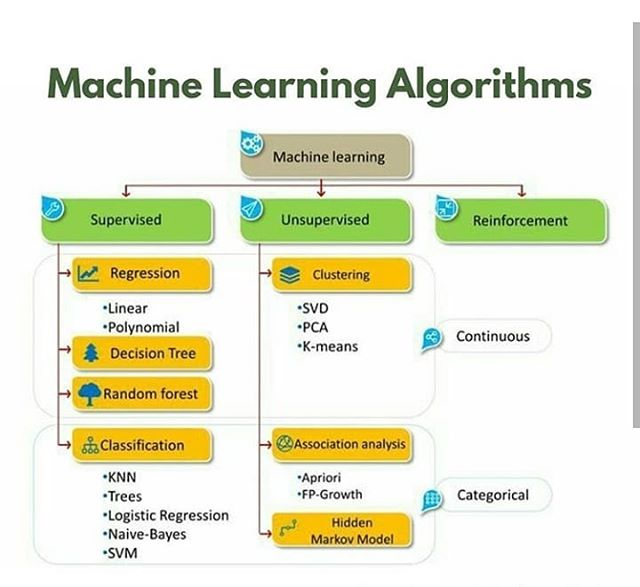
Step 3: Choose the Right Machine Learning Algorithm
The choice of algorithm depends on the type of problem and the nature of your data.
Commonly Used Algorithms:
- Linear Regression: For predicting continuous values
- Logistic Regression: For binary classification problems
- Decision Trees and Random Forests: For complex classification tasks
- Support Vector Machines (SVM): For clear-margin classification
- K-Means Clustering: For unsupervised grouping of data
- Neural Networks: For image, speech, and complex pattern recognition
Example: If you’re analyzing customer churn, a decision tree or logistic regression might be the best starting point.
Step 4: Train the Model
Once you’ve chosen an algorithm, it’s time to train your model on the dataset. Training involves feeding the algorithm with data so it can learn the relationships between input features and outputs.
Key Concepts in Training:
- Epochs: Number of times the algorithm works through the entire dataset
- Learning Rate: Speed at which the algorithm updates its weights
- Overfitting: When the model performs well on training data but poorly on new data
Best Practice: Use techniques like cross-validation and regularization to avoid overfitting.
Step 5: Evaluate Model Performance
Evaluating performance ensures your model is accurate and reliable. Different metrics are used depending on the problem type.
Metrics for Evaluation:
- Accuracy: Percentage of correct predictions (useful for classification)
- Precision & Recall: For imbalanced datasets (e.g., fraud detection)
- Mean Squared Error (MSE): For regression problems
- Confusion Matrix: To visualize classification results
Pro Tip: Always test your model on unseen data to ensure generalizability.
Step 6: Optimize and Tune Hyperparameters
Hyperparameters are configuration settings that impact how an algorithm learns. Examples include the number of decision tree branches or the learning rate in neural networks.
Methods for Optimization:
- Grid Search: Testing all combinations of parameters
- Random Search: Randomly selecting parameters to test
- Bayesian Optimization: Using probability models to guide search
Hyperparameter tuning often boosts accuracy and reduces error rates significantly.
Step 7: Deploy the Model
Once the model performs well, deployment integrates it into a real-world application. This step ensures your algorithm provides value in practical use.
Deployment Methods:
- APIs: Serving predictions through REST APIs
- Cloud Platforms: AWS SageMaker, Google AI Platform, Azure Machine Learning
- On-Premises Solutions: Useful for industries with strict data privacy needs
Step 8: Monitor and Maintain the Model
Machine learning models are not “set it and forget it.” Over time, data distributions change, and models may lose accuracy.
Maintenance Tasks:
- Track performance metrics
- Retrain with updated data
- Detect and fix data drift
- Ensure compliance with ethical AI practices
Practical Example: Implementing a Spam Detection Model
To illustrate the process, let’s consider building a spam email detector:
- Problem Definition: Classify emails as spam or not spam.
- Data Collection: Use labeled datasets with spam and non-spam emails.
- Data Preparation: Convert emails into numerical features (using TF-IDF).
- Algorithm Selection: Logistic Regression or Naïve Bayes.
- Training: Feed thousands of labeled examples.
- Evaluation: Use accuracy, precision, recall, and F1-score.
- Deployment: Integrate into an email client with real-time filtering.
- Monitoring: Continuously retrain with new email data.
Best Practices for Implementing Machine Learning Algorithms
- Start with simple models before moving to complex ones.
- Document every step for reproducibility.
- Prioritize ethical AI—avoid biased datasets.
- Always validate results with real-world testing.
Conclusion
Implementing machine learning algorithms may seem complex, but breaking the process into structured steps makes it manageable and effective. From defining the problem and preparing data to training, evaluation, and deployment, each stage is crucial for building reliable AI-powered systems.
As machine learning continues to shape industries, mastering the implementation process will open new opportunities for businesses and professionals alike.