Learn how to train machine learning models effectively with step-by-step guidance, best practices, and real-world applications for beginners and professionals.
Introduction
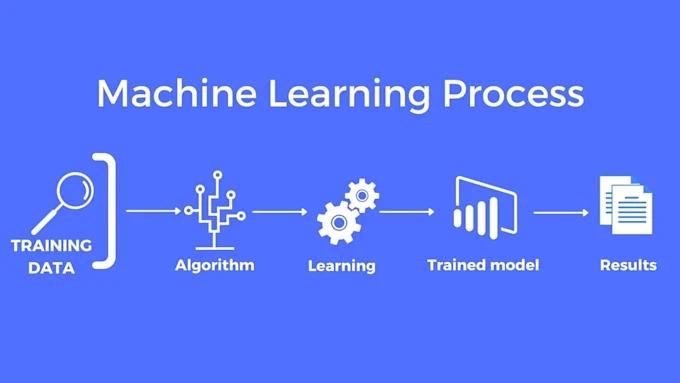
Machine learning (ML) is transforming industries by enabling systems to learn from data and make intelligent decisions without explicit programming. From personalized recommendations on Netflix to fraud detection in banking, ML powers many of the technologies we use daily. But how do you train a machine learning model?
Training an ML model involves preparing data, choosing the right algorithm, and optimizing it to make accurate predictions. Whether you’re a data science beginner or an AI enthusiast, understanding this process is essential. In this guide, we’ll walk through the step-by-step process of training machine learning models, explore common challenges, and provide actionable best practices.
Step 1: Define the Problem Clearly
Every successful machine learning project begins with a well-defined problem. Before gathering data or coding, you need to answer:
- What do you want to predict or classify?
- Is it a supervised learning problem (e.g., predicting house prices) or unsupervised learning (e.g., customer segmentation)?
- What will success look like (accuracy, precision, recall, etc.)?
Example: If you want to predict whether an email is spam or not, you’re working with a classification problem using supervised learning.
Step 2: Collect and Prepare the Data
Data is the foundation of every machine learning model. The better your data, the better your model will perform.
Sources of Data
- Internal databases: CRM systems, sales records, website analytics.
- Public datasets: Kaggle, UCI Machine Learning Repository.
- APIs: Twitter API, OpenWeather API, etc.
Data Preparation Steps
- Data cleaning – Handle missing values, remove duplicates, and correct inconsistencies.
- Feature engineering – Create new variables that better represent the problem (e.g., extracting day/month from a timestamp).
- Normalization and scaling – Standardize data to ensure features contribute equally.
- Data splitting – Divide into training, validation, and test sets (commonly 70%-15%-15%).
👉 Pro tip: Always keep a separate test set that the model has never seen for unbiased evaluation.
Step 3: Choose the Right Algorithm
Different problems require different algorithms. Choosing the right one depends on the type of data and the desired outcome.
Common Machine Learning Algorithms
- Linear Regression: Predicting continuous values (e.g., sales forecasting).
- Logistic Regression: Binary classification (e.g., spam detection).
- Decision Trees & Random Forests: Good for complex datasets.
- Support Vector Machines (SVM): Effective for classification with clear margins.
- Neural Networks: Ideal for deep learning tasks like image recognition and NLP.
When unsure, start with a simple algorithm and move to complex ones as needed.
Step 4: Train the Model
Training is where the model learns patterns from data. The steps include:
- Feeding training data into the algorithm.
- Adjusting weights/parameters to minimize error.
- Using optimization techniques like Gradient Descent.
During training, the model evaluates itself against the validation set to avoid overfitting (when the model memorizes data instead of learning patterns).
Step 5: Evaluate Model Performance
Evaluation ensures the model is not just memorizing data but generalizing well.
Common Evaluation Metrics
- Accuracy: Percentage of correct predictions.
- Precision & Recall: Useful for imbalanced datasets (e.g., fraud detection).
- F1-Score: Balance between precision and recall.
- Confusion Matrix: Visualizes classification performance.
- ROC Curve & AUC: Measures classification thresholds.
👉 For regression tasks, use Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE).
Step 6: Optimize and Fine-Tune
Even after training, models often need improvement. Techniques include:
- Hyperparameter tuning: Adjust parameters like learning rate, depth of trees, or number of layers in a neural network.
- Cross-validation: Ensures model stability across multiple data subsets.
- Regularization: Prevents overfitting by penalizing large coefficients.
- Feature selection: Remove irrelevant features to improve efficiency.
Tools for optimization:
- Grid Search – Exhaustive parameter testing.
- Random Search – Faster, randomized parameter tuning.
- Bayesian Optimization – More efficient parameter search.
Step 7: Deploy the Model
Once trained and optimized, the model is ready for deployment. This means integrating it into real-world applications.
Deployment Options
- APIs: Expose models via REST APIs.
- Cloud platforms: AWS SageMaker, Google Vertex AI, Azure ML.
- Edge deployment: Running models on IoT devices or mobile apps.
Ongoing monitoring is crucial. A model’s accuracy may decline over time due to changing data patterns, requiring retraining.
Challenges in Training Machine Learning Models
Training ML models isn’t always smooth. Some common challenges include:
- Overfitting: Model performs well on training data but poorly on new data.
- Data bias: Poor or unbalanced data can lead to unfair outcomes.
- High computational cost: Deep learning models often require GPUs.
- Lack of explainability: Complex models like neural networks can act as “black boxes.”
Best Practices for Training Machine Learning Models
To ensure long-term success, follow these best practices:
- Collect diverse and representative datasets.
- Start with simple models before moving to complex ones.
- Use automation tools like AutoML for faster experiments.
- Document your process and results for reproducibility.
- Continuously retrain and monitor model performance.
Conclusion
Training machine learning models is both an art and a science. It requires careful planning, high-quality data, the right algorithm, and rigorous evaluation. By following the steps outlined—defining the problem, preparing data, selecting an algorithm, training, evaluating, and deploying—you can build models that deliver real-world value.
Machine learning continues to reshape industries, and those who master it gain a significant competitive advantage. Whether you’re building predictive analytics for business or AI-powered apps, the ability to train machine learning models effectively is a skill worth mastering.